When bringing up a new hardware product and testing its functionality, you really start to get to know the “personality” of the hardware, including some of the unexpected bugs that come along with new hardware. Such is the case with my new uBMS board and the ESP32 driving the whole project.
The background
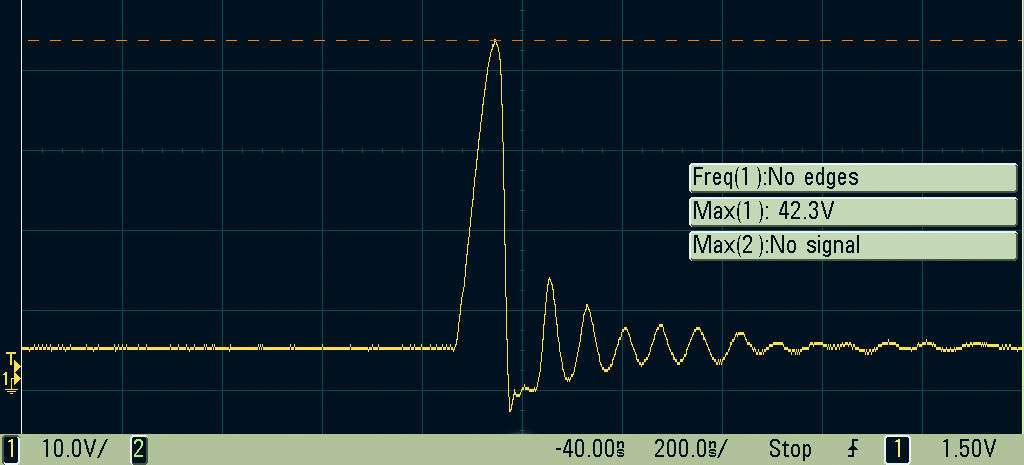
The other day, I set about finally testing out the balancing functionality of my board,in order to confirm that it works, and to collect data to allow me to estimate my current draw for a given PWM duty cycle. That way I could save on sensors, but also have reasonably accurate current measurements for each cell being balanced. This meant that for varying duty cycles, until I reached my current limit, I began collecting data of current for a given duty cycle. The funny thing I started to notice when I was collecting my data, however, is an error that would present itself as:rst:0x8 (TG1WDT_SYS_RESET),boot:0x13
…and then my ESP would then promptly reset.

